两表连接之嵌套循环连接
本文档主要介绍嵌套循环连接,因此先了解嵌套循环连接的一些基础知识,打好基础知识,才更容易学习。
1、概念:嵌套循环连接处理的两个数据集被称为外部循环(也叫驱动表)和内部循环,当外部循环执行一次的时候,内部循环需要针对外部循环返回的每条记录执行一次;
2、特性:在所有的数据返回之前,就可以返回结果的提一条数据;
可以有效的利用索引来处理限制条件与连接条件;
支持所有类型的连接;
3、优化器会按照一定的规则来决定两张表谁是驱动表、谁是被驱动表。
二、测试环境说明:数据库版本:11.2.0.3
表A1 NUM_ROWS 3,658,250(百万级别),没有索引脚本:create table hr.A1 as select * from all_objects;(然后运行以下脚本几次,产生大量的数据 insert into hr.a1 select * from hr.a1)
表B1 NUM_ROWS 100CREATE TABLE HR.B2(ID NUMBER)
测试方法:
通过HINT去改变ORACLE两表连接产生的执行计划,并对比几种执行计划的效率;(友情提示:执行计划的查看方法,请在本博客中查找)
测试一:b1为内表,运行嵌套循环连接
脚本:
select /*+ ordered use_nl(b1) */ *
from a1,b1
where a1.object_id=b1.id ;
执行计划:
<
解读:
外表A1运行一次后,执行一次B1的全表扫描,然后再根据条件进行过滤,外部表A1合计运行3658次的外部循环;
计划时间:16:35:25
测试二:a1为内表,运行嵌套循环连接
脚本:
select /*+ ordered use_nl(a1) */ *
from a1,b1
where a1.object_id=b1.id ;
执行计划:
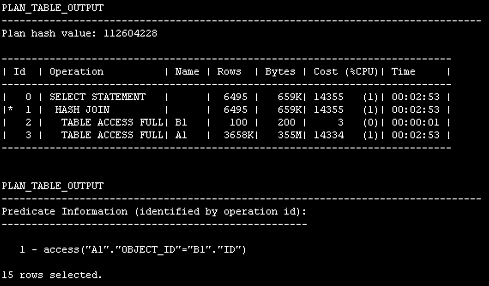
解读:
外表B1运行一次后,执行一次A1的全表扫描,然后再根据条件进行过滤,外部表B1合计运行100次的外部循环;
计划时间:00:02:53
结论一:在最简单的两表的嵌套循环连接过程中,行数较少的表应该为驱动表,会有更高的执行效率,但是这个行为是ORACLE本身来决定,而决定的这个动作主要由各表的统计信息,所以当对整个执行计划有疑问时,请检查统计信息是否正确;
测试三:连接条件增加索引,在表A1的object_id列上面增加索引;
脚本:
select /*+ USE_NL_WITH_INDEX(a1 A1_ID) */ *
from a1,b1
where a1.object_id=b1.id ;
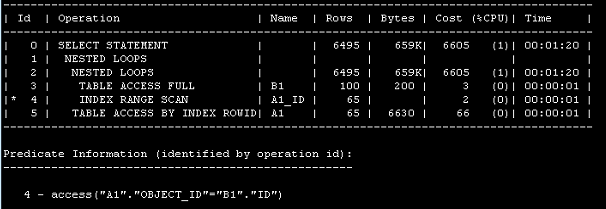
解读:当A1表增加索引后,外部表循环B1完成一次后,内表可以通过这个值去搜索索引,根据索引后的结果再到A1表获取数据,避免了全表扫描;
结论二:在嵌套循环连接中,连接条件中可以用到索引,如果内表的选择性很强,那么在调优的过程中,可以增加连接条件为索引;
【版权声明】
本站部分内容来源于互联网,本站不拥有所有权,不承担相关法律责任。如果发现本站有侵权的内容,欢迎发送邮件至masing@13sy.com 举报,并提供相关证据,一经查实,本站将立刻删除涉嫌侵权内容。